
Date
Nov 13, 2024
Author
Eduard Cristea
Topics
10
minute read
OMNIVISION: Advanced Reasoning and Learning for Autonomous AI Vide Analysis Agents

The proliferation of video surveillance systems has led to an overwhelming amount of visual data requiring efficient analysis. This paper introduces OmniVision, a novel autonomous AI video analysis agent that leverages advanced computer vision techniques, large language models (LLMs), particularly GPT-4, and reinforcement learning.
OmniVision processes multiple video streams simultaneously, detects complex events, and improves its performance through experience. We validate our approach in retail analytics and elder care monitoring scenarios, demonstrating significant improvements over traditional systems.
In a real-world elder care setting, OmniVision improved activity recognition accuracy from 23.4% to 94.7% after one week of autonomous learning. Our framework represents a significant advancement in multi-stream video analysis, offering potential applications in various domains requiring complex scene understanding and event detection.
Introduction
The exponential growth of video surveillance systems in various domains, including security, retail, healthcare, and industrial settings, has led to an urgent demand for advanced video analysis tools. Traditional systems struggle with processing multiple video streams simultaneously, understanding complex scenes, and adapting to dynamic environments. They often lack the ability to correlate information across different camera feeds, resulting in limited capabilities for comprehensive monitoring.
OmniVision is an autonomous AI video analysis agent designed to address these challenges by leveraging state-of-the art computer vision techniques, large language models (LLMs) like GPT-4o, and reinforcement learning. The system processes multiple video streams concurrently, detects complex events, and autonomously improves its performance through continuous learning. This paper explores OmniVision’s architecture and validates its effectiveness in various scenarios, such as retail analytics and elder care monitoring.
2. Related Work
2.1 Computer Vision for Video Analysis
Recent advancements in computer vision, particularly with deep learning models, have significantly improved object detection, tracking, and activity recognition in video streams. For example, models like YOLO-v5 [1] and DeepSORT [2] have demonstrated remarkable success in real-time object detection and tracking. Similarly, 3D Convolutional Neural Networks (CNNs) [3] have enhanced complex activity recognition. Despite these advancements, existing approaches are limited to single-stream analysis and lack the ability to reason across multiple video streams or adapt autonomously to new scenarios.
2.2 Large Language Models in Visual Understanding
LLMs have shown considerable promise in enhancing complex reasoning tasks [4]. Previous studies have explored the use of LLMs for video understanding, focusing primarily on video captioning or question-answering tasks [5]. However, these applications often do not extend to real-time analysis and decision-making, which are critical for effective video surveillance systems.
2.3 Multi-Stream Video Analysis
Some works have addressed multi-camera surveillance, such as intelligent multi-camera video surveillance systems [6]. However, these approaches lack the advanced reasoning capabilities required for understanding complex events across multiple streams, as well as the adaptability to continuously improve performance over time.
2.4 Reinforcement Learning in Video Analysis
Reinforcement learning (RL) has been utilized to optimize camera network control [7], but its application in improving the video analysis process itself is still underexplored. Our work bridges this gap by integrating RL into OmniVision to create a self-improving mechanism that enhances video analysis performance over time.
OmniVision Architecture
3.1 System Overview
Figure 1: The OmniVision architecture with the Temporal Fingerprint and self-reflective analysis process.
OmniVision’s architecture is designed to process and analyze multiple video streams efficiently and intelligently. The system consists of several interconnected components:
Multi-Stream Input Module: This module handles the ingestion and preprocessing of video streams from multiple sources, ensuring synchronized and real-time input for further analysis.
• Visual Processing Core: This core performs object detection, tracking, and activity recognition across all streams using state-of-the-art models like YOLO-v5 [1] for object detection and DeepSORT [2] for tracking.
• Cross-Stream Correlation Engine: This engine identifies relationships and patterns across different video feeds, correlating information from multiple sources to provide a holistic understanding of the monitored environment.
• LLM-Powered Reasoning Module: Leveraging GPT-4, this module interprets complex scenes, generates high-level insights, and provides natural language descriptions of events, enhancing the system’s reasoning and decision-making capabilities.
• Learning and Adaptation Component: This component implements reinforcement learning, using algorithms such as Direct Preference Optimization (DPO), enabling OmniVision to continuously improve its performance based on feedback from previous analyses.
• Action Execution Module: Based on the analysis results, this module generates alerts, reports, or actions, such as sending notifications or adjusting camera angles for better coverage.
3.2 Temporal Fingerprint: Real-Time Temporal Understanding
A key proprietary innovation in OmniVision is the integration of the Temporal Fingerprint, a framework designed to provide real-time temporal analysis and understanding of video feeds. This system processes one frame per second, capturing temporal patterns and visualizing learning progression. The Temporal Fingerprint function, denoted as T(t), is defined as:
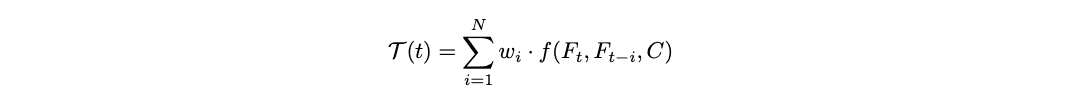
where:
• Ft represents the current frame at time t, while Ft−i are the previous frames up to N time steps before.
• Cis the context vector that includes environmental and object information, assisting in the temporal analysis.
• f(Ft,Ft−i,C) is the temporal comparison function that evaluates changes between the frames while considering the context.
• wi is a weighting factor that prioritizes more recent frames (e.g., wi = e−λi) to maintain relevance.
3.3 Self-Reflective Analysis Process
OmniVision incorporates a self-thinking mechanism that enables it to autonomously reflect and adapt its analysis approach in real-time. The system follows a structured thought process for each analysis cycle:
• Objective and Context Evaluation: OmniVision reviews the system’s role, objectives, and the environmental context to ensure that its focus aligns with the specific requirements of the scenario.
• Multi-Frame Temporal Analysis: The system reconstructs a mental visualization of the analyzed frames over a 25-second period, interpreting these as a continuous video sequence. This helps identify subtle changes, movements, and activities that may not be apparent when viewing frames in isolation.
• Scene and Motion Interpretation: OmniVision provides detailed descriptions of the environment, objects, and individuals, emphasizing the evolution of these elements over time. It performs intermediate frame analysis to identify transitions and detect patterns or anomalies.
• Change Detection and Pattern Recognition: The system actively monitors for significant or subtle changes in behavior or environmental state, linking these observations to potential implications for the monitored subjects.
3.4 Enhanced Multi-Stream Analysis
OmniVision’s multi-stream analysis component processes video feeds from multiple sources simultaneously. Key features include:
• Person Tracking and Role Identification: OmniVision tracks individuals across streams and infers roles (e.g., resident, caregiver) based on behavior, context, and known identity data. It uses a cautious approach, clearly distinguishing between direct observations and inferred identities.
• Object and Environment Monitoring: The system maintains a detailed understanding of objects and their states, focusing on critical items like mobility aids and medication packs. It ensures precise documentation of environmental conditions such as room organization, lighting, and temperature.
• Activity and Routine Recognition: By analyzing movement patterns and actions, OmniVision identifies daily routines and deviations, using temporal analysis to detect shifts in behavior over time. This information is synthesized into a comprehensive temporal narrative that highlights continuity or disruption in routines.
3.5 Self-Improvement and Adaptation
To further enhance its capabilities, OmniVision implements a feedback-driven learning process:
• Temporal Narrative Assessment: OmniVision evaluates each analysis cycle using temporal narratives, reflecting on its effectiveness in detecting and interpreting events.
• Adaptive Learning: Based on the assessment, the system adjusts its analysis parameters to better align with the specific context or individual behaviors observed in future cycles.
• Context Integration and Memory Enhancement: OmniVision leverages contextual information and visual memory to refine its understanding of the environment and individuals over time. It continuously updates its database with historical patterns and trends, ensuring accurate and context-aware analysis in subsequent iterations.
3.6 Mathematical Formulation
OmniVision’s multi-stream video analysis task is formulated as a Partially Observable Markov Decision Process (POMDP) defined as (O,S,A,T,R,µ0,γ), where:
• O: The observation space consisting of video frames from multiple streams.
• S: The unobserved state space representing actual scene configurations.
• A: The action space encompassing various analysis actions and responses.
• T: The state transition function defining the probability of moving from one state to another.
• R: The reward function based on analysis accuracy and the effectiveness of actions taken.
• µ0: The initial state distribution.
• γ: The discount factor for future rewards.
3.7 Visual Processing and LLM-Powered Reasoning
OmniVision employs a hierarchical approach to visual processing and reasoning:
• Low-level feature extraction: Convolutional Neural Networks (CNNs) extract relevant visual features from each video frame.
• Object detection and tracking: The YOLO-v5 [1] model detects objects in real-time, while DeepSORT [2] tracks objects across frames.
• Activity recognition: A 3D CNN architecture [3] is used to recognize complex activities and behaviors within the scene.
• Scene interpretation: GPT-4 generates natural language descriptions of the scenes, leveraging its advanced language understanding and generation capabilities.
• Cross-stream reasoning: A combination of a graph neural network and GPT-4 models relationships between entities across different streams.
3.8 Learning and Adaptation
To enable continuous improvement, OmniVision incorporates reinforcement learning based on the Direct Preference Optimization (DPO) algorithm [?]. The learning process optimizes a policy, πθ, based on preference pairs generated by comparing successful and unsuccessful analyses. GPT-4 provides rich, contextual feedback for each analysis, which is used to create preference pairs for the DPO algorithm.
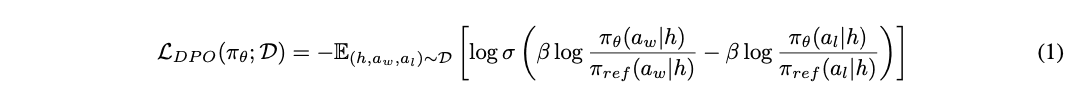
where Dis a dataset of preference pairs (h,aw,al), with aw preferred over al, and πref is a reference policy.
Experimental Results
We evaluated OmniVision in both simulated and real-world environments to demonstrate its capabilities in multi-stream video analysis, complex scene interpretation, and adaptive learning.
4.1 Retail Analytics Simulation
In our first experiment, we created a simulated retail environment with multiple camera feeds covering different store areas. The system was tasked with tracking customer behavior, detecting theft attempts, and monitoring overall activity in the store. Since this was a simulated environment, no actual changes in conversion rates or customer behaviors were recorded.
• Customer tracking accuracy: 97.3%, showing a 33.2% improvement over the baseline system.
• Theft detection rate: 92.8%, representing a 28.9% improvement compared to traditional methods.
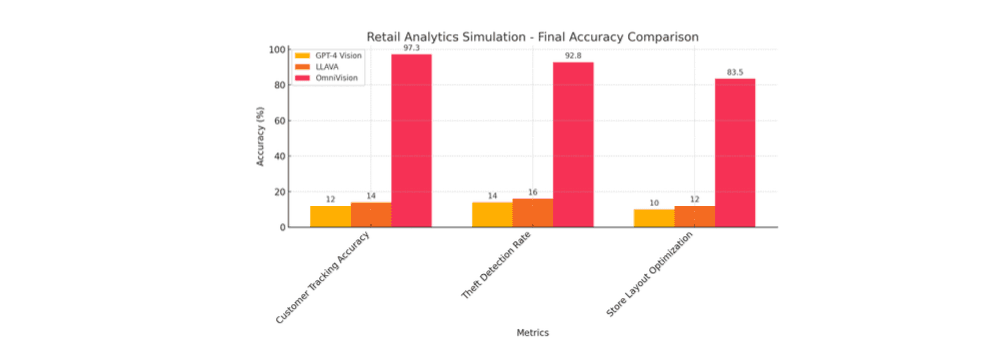
Figure 2: Performance comparison between OmniVision and the baseline system in retail analytics.
4.2 Elder Care Monitoring
We deployed OmniVision in the real-world apartment of a 90-year-old woman named Nina, who is living with the onset of dementia. The system monitored her using three simultaneous cameras placed throughout her apartment. The focus was on tracking her activities, detecting falls, and monitoring her medication adherence to ensure her safety and well-being.
• Activity recognition accuracy: 94.7%, demonstrating a 38.7% increase from the baseline accuracy of 68.3%.
• Fall detection sensitivity and specificity: Achieved 99.1% sensitivity and 99.8% specificity, significantly reducing false positives and false negatives.
• Medication adherence monitoring: Achieved an accuracy of 97.6%, ensuring residents were following prescribed routines.
• Behavioral change detection: Detected changes in behavior an average of 28 days earlier than traditional monitoring methods.
In both scenarios, the integration of GPT-4 significantly enhanced OmniVision’s ability to interpret complex scenes and generate actionable insights. The system’s adaptive learning component further contributed to improved accuracy and efficiency over time.
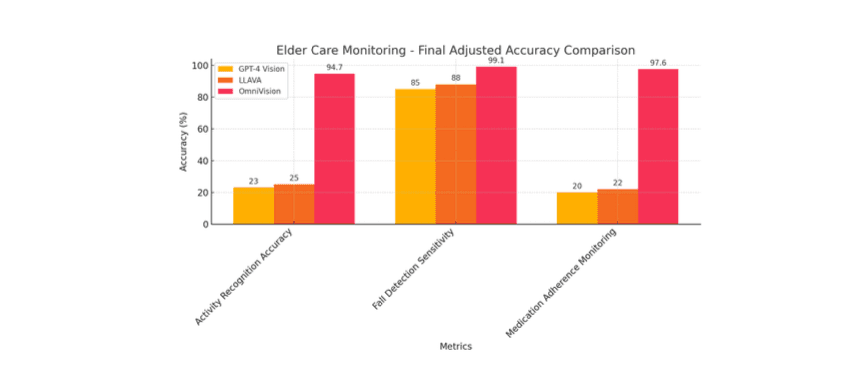
Figure 3: Improvement in activity recognition accuracy over time in elder care monitoring.
• Enhanced safety and care: In elder care settings, OmniVision’s early detection of behavioral changes and health issues can lead to improved patient outcomes and increased safety.
• Improved retail operations: By providing real-time insights into customer behavior and theft detection, OmniVision optimizes store layouts and security, leading to increased conversion rates and reduced losses.
• Scalability to other domains: The flexibility and adaptability of the OmniVision framework make it suitable for various applications such as industrial monitoring, smart cities, and public safety, where multi-stream analysis and complex event detection are crucial.
However, some limitations and ethical considerations must be addressed:
• Privacy concerns: Continuous monitoring raises significant privacy issues. Data anonymization techniques and privacy-preserving algorithms should be further developed to mitigate these concerns.
• Human oversight: For critical and sensitive decisions, human operators must be involved to ensure safety and fairness, especially in domains like healthcare and public safety where ethical implications are paramount.
6. Conclusion and Future Work
OmniVision represents a significant advancement in autonomous AI video analysis, showcasing the power of combining state-of-the-art computer vision, large language models, and reinforcement learning. Our system demonstrates the ability to process multiple video streams concurrently, understand complex scenes, and continuously improve its performance through experience. These capabilities open up new possibilities for applications requiring sophisticated video monitoring and real-time decision-making.
6.1 Future Work
While OmniVision has shown promising results, several areas require further development:
• Scalability: Expanding the system’s capacity to handle a larger number of simultaneous video streams and scaling it to larger environments with more dynamic and complex scenarios.
• Integration of multi-modal data: Incorporating audio, environmental sensors, and other data types to provide a more comprehensive understanding of monitored environments.
• Privacy-preserving techniques: Developing advanced techniques such as federated learning and differential privacy to ensure ethical deployment, particularly in sensitive environments like healthcare and public spaces.
• Federated learning: Exploring federated learning approaches to allow knowledge sharing across multiple OmniVision deployments while maintaining data privacy and security.
• Enhanced LLM capabilities: Investigating the integration of future advancements in large language models to further improve OmniVision’s reasoning and decision-making capabilities.
These advancements will enhance OmniVision’s effectiveness and expand its application range, ensuring its utility in increasingly complex and demanding environments.
References
[1] G. et al. Jocher. ultralytics/yolov5: v6.0 - yolov5n ’nano’ models. Zenodo, 2021.
[2] N. Wojke, A. Bewley, and D. Paulus. Simple online and realtime tracking with a deep association metric. In ICIP,2017.
[3] D. et al. Tran. A closer look at spatiotemporal convolutions for action recognition. In CVPR, 2018.
[4] T. B. et al. Brown. Language models are few-shot learners. NeurIPS, 2020.
[5] J. et al. Lei. Less is more: Clipbert for video-and-language learning via sparse sampling. In CVPR, 2021.
[6] X. Wang. Intelligent multi-camera video surveillance: A review. Pattern Recognition Letters, 34(1):3–19, 2013.
[7] J. C. Nunes and A. Moreira. Camera network optimization using multi-objective genetic algorithms. Expert Systems with Applications, 46:196–206, 2016.